What is robots.txt & why is it important for SEO?
Make your site easier to crawl, faster to index, and safer to manage with a well-optimized robots.txt file.
Published May 21, 2025
AI Summary
If we want our website to show up in Google search, we need to make sure it’s indexable—but not every page should be. Sometimes, there are parts of a site we don’t want crawled and indexed, such as admin pages, staging environments, or duplicate content.
That’s where the robots.txt file comes in. It’s a simple yet powerful tool that tells search engine crawlers which pages to access and which to leave alone.
In this guide, we’ll break down how robots.txt files work, why they matter for SEO, and how to create one yourself. It might sound technical, but with the right know-how, it's easier than you think.
Key takeaways
- A robots.txt file helps control which parts of your website search engine crawlers can and can’t access.
- A well-optimized file improves crawl efficiency and protects content not meant for search.
- Robots.txt syntax is simple, but a single typo can block important pages from search.
- Maintaining an error-free robots.txt file is important for SEO performance.
Increase ROI from organic traffic
Maximize conversions across your content pages by automating testing, tracking, optimization, and attribution.
Book a demoWhat is a robots.txt file?
A robots.txt file is a simple text file placed in the root directory of your website that serves as a set of instructions for search engine crawlers.
Its main job is to guide these crawlers to the pages you want indexed while keeping them away from content that shouldn’t appear in search results, like internal admin panels, duplicate pages, or test environments.
Without it, bots might crawl and index parts of your site that aren’t meant for public view, potentially harming your SEO or exposing sensitive data.
While not all crawlers respect these directives, Googlebot and most major search engines do follow them closely, making this file an essential part of any well-optimized site that wants to get consistent traffic from search.
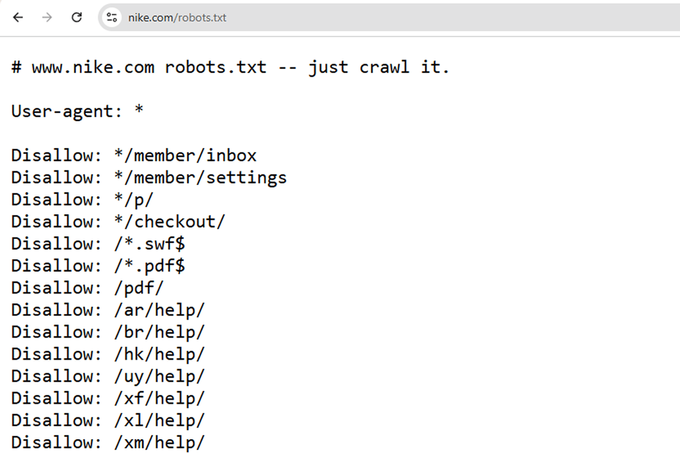
To view any site's robots.txt file, just add /robots.txt to the end of the domain (e.g., example.com/robots.txt) like in the example below.
» Learn how to ask Google to index your site.
Why is robots.txt important for SEO?
At its core, a well-crafted robots.txt file helps ensure search engines focus their attention on the right parts of your site. Other than blocking sensitive or irrelevant content, it allows us to give bots clear directions so they crawl efficiently and don’t waste time (or resources) on pages that don’t add SEO value.
Here’s why it matters:
- Control crawler activity: Robots.txt gives us a way to prevent crawlers from accessing areas not meant for public view, like login pages, internal dashboards, or development and staging environments.
- Optimize crawl budget: Search engines have a limited number of pages they’ll crawl on your site in a given timeframe—this is your crawl budget. By telling bots to ignore low-value or redundant pages, we help them prioritize the pages that actually matter for SEO.
- Keep unnecessary content out of the index: Duplicate content, internal search results, and user-specific areas don’t need to show up in search. Disallowing these keeps your index clean and focused.
- Block specific file types: You can also use robots.txt to prevent bots from indexing certain file types, like PDFs, images, or gated assets used for SEO lead generation.
- Point bots to your sitemap: Including a link to your XML sitemap in your robots.txt file makes it easier for bots to discover your site structure and prioritize important URLs.
- Reduce server load: Every bot request uses server resources. By limiting access to only what’s necessary, you reduce the strain on your infrastructure—especially important for large sites with lots of traffic.
In short, the robots.txt file helps you manage how search engines interact with your site, which can improve efficiency, protect sensitive areas, and support better SEO performance.
READ MORE: A guide to Google's Crawl Stats report
How robots.txt files work
Robots.txt files work by giving search engine bots a set of rules to follow when they crawl your site.
When a bot visits your website, one of the first things it does is check the robots.txt file. Based on the instructions it finds there, the bot will either proceed to crawl certain pages or skip over them.
The robots.txt file is made up of fairly straightforward directives—User-agent to specify which bot the rule applies to, and Disallow or Allow to indicate which parts of the site should be blocked or accessible (more on this below).
For example, this directive tells bots not to crawl anything in the /admin/ directory:
User-agent: *
Disallow: /admin/
» Talk to an SEO expert for help with your robots.txt file.
Robots.txt syntax explained
The syntax of a robots.txt file is fairly straightforward and easy to understand, but it’s also strict. Even a small typo or a single wrong-case letter can lead to search engines misinterpreting your instructions. While directives like Disallow aren’t case-sensitive, the paths you use are (e.g., /admin/ is different from /Admin/).
Here’s a breakdown of the key directives and how to use them effectively.
The user-agent directive
This directive defines which search engine crawler the following rules apply to.
To target all bots:
User-agent: *
To target a specific bot (e.g., Googlebot):
User-agent: Googlebot
The disallow directive
This directive prevents bots from crawling a specific path on your site.
To block bots from accessing any URLs that begin with /admin/:
Disallow: /admin/
To block the entire site:
Disallow: /
The allow directive
This directive permits bots to access a path, even if a broader Disallow rule exists.
For example:
Disallow: /images/
Allow: /images/logo.png
This blocks the /images/ directory but makes an exception for logo.png.
The sitemap directive
This directive provides the location of your XML sitemap to help bots discover all crawlable pages.
Sitemap: https://www.example.com/sitemap.xml
The crawl-delay directive (not supported by Googlebot)
This directive tells bots how many seconds to wait between crawl requests to avoid overloading your server.
For example:
Crawl-delay: 120
This instructs compliant bots to wait 120 seconds between each request.
READ MORE: A guide to internal linking
How to use wildcards
A wildcard is a special character that allows you to create flexible rules that match multiple URLs or patterns, rather than having to list each specific URL individually.
There are two primary wildcard characters used in robots.txt: an asterisk (*) and a dollar sign ($).
* is a wildcard that matches any string of characters.
To block all PDF files in the /private/ directory:
Disallow: /private/*.pdf
$ matches the end of a URL.
To block all URLs that end in .jpg:
Disallow: /*.jpg$
Now, let's put it all together.
Here’s an example of a well-structured robots.txt file that uses the directives we covered above:
User-agent: *
Disallow: /admin/
Disallow: /private/
Disallow: /search
Disallow: /dev/Disallow: /staging/
Disallow: /*.pdf$
Allow: /images/logo.png
Sitemap: https://www.example.com/sitemap.xml
What this file does:
- Applies the rules to all bots (User-agent: *).
- Blocks access to sensitive or non-public directories like /admin/, /private/, /dev/, and /staging/.
- Blocks internal search results pages (/search).
- Blocks all URLs that end in .pdf, no matter where they are on the site.
- Allows access to a specific file (logo.png) in an otherwise disallowed folder.
- Points bots to the site’s XML sitemap for easier discovery of crawlable URLs.
» Explore our list of the top SEO KPIs to track this year.
How to create a robots.txt file
Creating a robots.txt file is simple, but there are a couple of important rules to follow.
First, make sure the file is named exactly "robots.txt"—all lowercase, with no extra characters or variations. It's case-sensitive, so "Robots.txt" or "robots.TXT" won’t work.
Next, place the file in the root directory of your website’s main server. That means it should be accessible at https://www.yourdomain.com/robots.txt. If it’s stored in a subfolder or named incorrectly, search engine crawlers won’t be able to find or follow it.
You can create the file in any plain text editor, add your directives, and upload it to your server via FTP or through your hosting platform’s file manager. Once it's live, double-check that it’s accessible in the browser by visiting /robots.txt on your domain or use Google's robots.txt testing tool.
» Find out how to fix "discovered – currently not indexed."
8 key robots.txt best practices
To make sure your robots.txt file works as intended and supports your SEO goals, here are a few best practices to follow:
- Place it in the top-level directory: Your robots.txt file must live at the root of your domain (e.g., yourdomain.com/robots.txt). Bots won’t look for it in subfolders.
- Remember it's case-sensitive: Both the file name and the URLs listed inside are case-sensitive. Always use "robots.txt" in lowercase, and match URL paths exactly.
- Avoid conflicting rules: Don’t mix messages—like allowing and disallowing the same path—since bots may not interpret the conflict in your favor.
- Know that not all bots listen: Most major search engines respect robots.txt, but some less reputable bots may ignore it. Don’t rely on it for security—use authentication or other methods to protect sensitive areas.
- Link to your sitemap: Add a sitemap directive right at the top or bottom of the robots.txt file (we recommend the bottom, but it's up to your personal preference). This helps bots discover and crawl your content more efficiently.
- Don’t include sensitive information: Since your robots.txt file is publicly accessible, avoid listing private or sensitive URLs—this can unintentionally draw attention to them.
- Use separate files for subdomains: Each subdomain (like blog.example.com) needs its own robots.txt file to control how bots crawl it.
- Test after every change: Use Google’s robots.txt testing tool in Search Console to check for errors or unintended blocks. A small mistake can keep important pages out of search results.
Following these tips will help ensure your robots.txt file supports SEO without creating indexing issues.
» Learn how to stay ahead of the changes coming to Google Search.
Get your robots.txt file right
Now that you understand what robots.txt files do and how they work, it's the perfect time to make sure yours is doing its job. An optimized, error-free robots.txt file helps search engines crawl your site efficiently, boosting SEO performance and protecting parts of your website that shouldn’t be indexed.
A small mistake can have big consequences, so take the time to review and fine-tune your robots.txt file to keep your site running smoothly.
» Need help with robots.txt files? Book a free consultation.




